고정 헤더 영역
상세 컨텐츠
본문
제약 조건이란?
컬럼들 간의 제한사항을 관리하고, 조건을 위반하는 데이터를 방지하여 '데이터의 무결성'을 보장하는 규칙을 말한다. 이를 통해 데이터가 결함없이 정확하고 완전한 상태임을 나타낼 수 있다.
예를 들어 한 어플에서 여러 사용자의 회원가입 관리를 한다고 해보자.
중복된 이메일 허용이나, 다른 데이터들로도 사용자들을 정확하게 구분할 수 없다면 특정 사용자의 정보 조회가 불가능할 것이다.
이러한 상황을 방지하기 위해 제약조건이 적용된다.
뿐만 아니라 제약 조건의 명시적 표현을 통해 해당 테이블이 어떤 역할을 하는지, 어떤 데이터를 저장하는지 인지할 수 있게 도와주는 역할 또한 가지고 있다.
제약 조건의 종류
1. 고유 제약 조건 Unique
테이블에 소속된 특정 컬럼이 중복된 키를 가질 수 없는 조건을 말한다.
사용자의 이메일이나 아이디 등의 고유한 정보가 이에 해당한다.
2. NULL 제약 조건
특정 컬럼이 아무 값을 입력받지 않아도 되도록, 혹은 반드시 입력받도록 정한다.
NULL 을 허용할 경우 데이터를 입력받지 않을 때 NULL 값으로 저장해 '데이터가 없음' 을 나타낸다.
3. 기본 키 Primary Key
DB를 설계하다보면 반드시 사용하게 되는 조건이다.
테이블 내에서 각 행을 고유하게 식별할 수 있도록 보장하는 조건을 말한다.
이전에 봤던 'AUTO_INCREMENT' 명령어가 쓰인 컬럼이 이 Primary Key 이다.
4. 외래 키 Foreign Key
테이블 간의 관계를 설정하는 조건을 말한다.
특정 컬럼을 기준으로, 한 테이블의 컬럼이 다른 테이블의 특정 컬럼을 참조하도록 한다.
이를 통해 테이블 간의 1:1, 1:N, N:M 등의 조건을 설정할 수 있다.
예시 상황 : 음식 주문앱 DB 설계
우리는 요구사항으로 간단히 '고객은 1개의 음식을 주문할 수 있다' 라고 설정해보자.
1. 각 주체의 테이블 설계
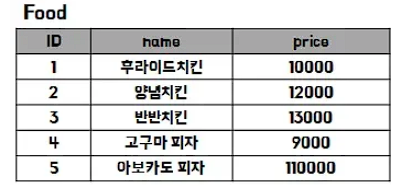
필요한 테이블은 당장은 2가지, 고객의 정보를 저장할 고객 테이블과 주문 가능한 음식을 저장하는 음식 테이블이 있을 것이다.

2. 연관 관계 고민
준비된 두개의 테이블이 어떤 관계로 연결되어야 하는지에 대해서이다.
고객이 음식을 주문할 때, 주문 정보는 과연 어느 테이블에 들어가야 하는지 고민해보자.
먼저 고객 테이블에 주문 정보를 저장한다고 하면

한 사람이 여러 번의 주문을 했을 때 name 값이 중복 조회되는 현상이 발생한다.
그럼 음식 테이블에 저장한다면 어떨까?
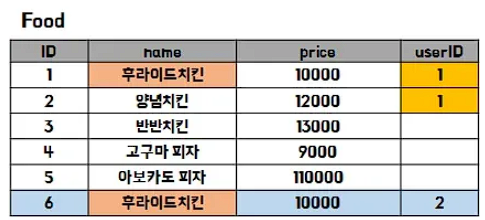
주문 가능한 음식을 나타내야 하는 테이블이, 여러 손님이 같은 메뉴를 시켰을 때 메뉴 이름이 중복되게 된다.
따라서 제일 최적의 답안은 '주문' 만을 위한 테이블을 별도로 추가하는 것이다.

[손님 1명은 N개의 주문이 가능하다] 는 점은 손님 테이블과 주문 테이블이 1 : N 의 관계임을 나타낸다.
[음식 1개는 주문 N개에 포함이 가능하다] 는 점은 음식 테이블과 주문 테이블이 1 : N 의 관계임을 나타낸다.
따라서 이 정보를 조합했을 때, 손님 테이블과 음식 테이블은 N : M 의 관계라고 표현할 수 있다.
3. ERD 작성
ERD란, Entity Relationship Diagram 의 줄임말로, DB의 모델링 과정을 그림으로 나타낸 것을 말한다.
예시로 들었던 손님/음식/주문 테이블을 ERD로 표현하면
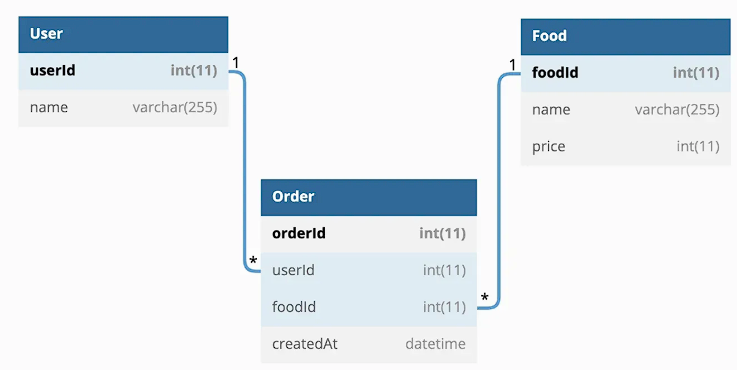
다음처럼 나타낼 수 있을 것이다.
여기서 * 표시가 보일 텐데, 이는 N 개의 의미를 뜻하며 1이라고 써져있는 반대 테이블간의 관계가 1 : N 임을 나타낸다.
그럼 이를 토대로 테이블의 스키마를 작성해보면
CREATE TABLE Users
(
userId int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(255) NOT NULL UNIQUE
);
CREATE TABLE Food
(
foodId int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(255),
price int(11)
);
CREATE TABLE Orders
(
orderId int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
userId int(11) NOT NULL,
foodId int(11) NOT NULL,
createdAt datetime NOT NULL DEFAULT NOW(),
FOREIGN KEY (foodId) REFERENCES Food (foodId)
ON DELETE NO ACTION
ON UPDATE CASCADE,
FOREIGN KEY (userId) REFERENCES User (userId)
ON DELETE NO ACTION
ON UPDATE CASCADE
);다음처럼 나타낼 수 있다.
orders 테이블을 보면 Foreign Key 를 통해 외부 요소를 가져오는 방법을 사용했다. 이를 통해 테이블 간의 관계를 나타내는 것인데, 먼저 제약 조건들부터 확인하고 넘어가보자.
제약 조건
1. Primary Key
이 기본 키를 사용하지 않으면 데이터마다 고유 정보가 존재하지 않아서 테이블 생성이 불가능하다.
말 그대로 필수적인 속성인 것이다.
User 테이블
1. userId 컬럼을 기본 키로 설정
2. name 컬럼 존재
CREATE TABLE Users
(
userId int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(255) NOT NULL UNIQUE
);다음과 같이 작성 후 실행하면
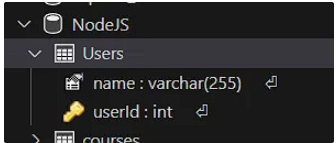
이렇게 Users 테이블에 두개의 컬럼이 나타난다. userId 를 보면 키 모양의 아이콘이 보이는데, 이것이 Primary Key 가 적용됨을 나타낸다.
테이블이 정상적으로 생성된 것을 확인하려면
desc Users;다음 쿼리문을 실행해보면 알 수 있다.
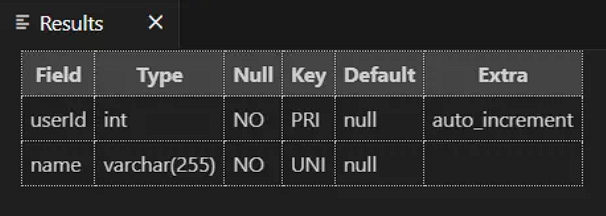
이렇게 2개의 필드(컬럼) 이 적용되어 있고 각각의 타입과 NULL 허용하는지, Key 속성 등이 나타난다.
2. 고유 제약 조건
처음에 말했던 것처럼 이 고유 제약 조건 Unique 는 특정 컬럼에서 중복된 값이 허용되지 않도록 설정하기 위해 사용한다.
예를 들어 로그인 시도를 하는데 이메일이 중복 허용일 경우 사용자 식별을 위해 이메일 뿐만 아니라 이름, 계정 생성 시기 등 다른 데이터들을 더 받아와야 정확한 데이터 식별이 가능할 것인데 얼핏 봐도 너무 번거로운 동작이다.
해서 애초부터 이메일이 중복되지 않도록 하여 사용자 식별을 용이하게 만드는 것이다.
Users 테이블에 name 값에 UNIQUE 키워드를 작성하여 고유 제약 조건을 설정하였는데, 정상 작동되는지 확인하려면
INSERT INTO Users (name) VALUES ('이용우');
INSERT INTO Users (name) VALUES ('이용우');
중복 데이터를 넣어볼 수 있다.

실행하면 이렇게 에러가 나타난다.
Users 테이블의 name 컬럼에 '이용우' 라는 값이 중복되었다 라고 알려주고 있다.
3. 외래 키 제약 조건
테이블 간의 관계를 나타내기 위해 사용한다고 하였는데, 어떤 양식으로 작성하는지부터 봐보자.
CREATE TABLE 테이블명
FOREIGN KEY (컬럼명) REFERENCES 참조_테이블명 (참조_컬럼명)
ON DELETE [연계 참조 제약 조건]
ON UPDATE [연계 참조 제약 조건]
);다음과 같이 테이블 생성 시 하단에 해당 테이블의 컬럼과 참조하려는 컬럼, 테이블을 명시하여 작성한다.
ON DELETE 와 ON UPDATE 는 참조하는 데이터가 삭제/수정 되었을 경우 어떤식으로 동작해야되는지를 표시한다.
이 외래 키의 경우만 다른 예제를 진행해보자면

다음 요구사항이 있다고 해보자.
이 경우 코드는
CREATE TABLE Garden
(
gardenId INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
address VARCHAR(255) NOT NULL
);
CREATE TABLE GardenPlants
(
gardenPlantsId INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
gardenId INT(11) NOT NULL,
name VARCHAR(255) NOT NULL,
FOREIGN KEY (gardenId) REFERENCES Garden (gardenId)
);이처럼 작성할 수 있다.
GardenPlants 테이블에서 gardenId 컬럼이 외래 키로, Garden 테이블의 gardenId 컬럼을 참조함을 나타내고 있다.
이 코드에서는 ON DELETE 나 ON UPDATE 에 대해서는 별도로 작성해주지 않았는데, 이에 대해서 추가적으로 알아보자.
연계 참조 무결성 제약 조건
데이터들을 관리하다보면 테이블 간의 연결관계가 있음에도 delete 메서드 등으로 데이터를 삭제하거나 update 메서드로 새롭게 변경되는 경우가 빈번히 발생한다.
이런 경우에 다른 테이블에서 이 컬럼을 참조하고 있었다면 문제가 발생할 수 있어, 이런 경우에 어떤 행위를 해야하는지 미리 설정하는 것을 '연계 참조 무결성 제약 조건' 이라고 말한다.
1. CASCADE
참조하는 객체가 변경/삭제될 경우 함께 변경/삭제 될 것을 나타낸다.
예를 들어 사용자 데이터가 삭제될 경우, 그 사용자의 음식 주문 내역 또한 함께 삭제되는 것이다.
FOREIGN KEY (userId) REFERENCES Users(userId)
ON DELETE CASCADE
ON UPDATE CASCADE;
2. NO ACTION
말 그대로 참조 데이터의 여부와 상관 없이 아무 행위도 하지 않는다는 것인데, 이를 통해 에러를 의도적으로 발생하게 하여 후속 조치를 기다리기도 한다.
예를 들어 사용자 데이터를 삭제하려고 하는데, 그 사용자의 주문 내역이 아직 남아있다면 데이터 삭제를 막는다.
FOREIGN KEY (userId) REFERENCES Users(userId)
ON DELETE NO ACTION
ON UPDATE NO ACTION;
3. SET NULL
참조 데이터가 변경/삭제될 경우 데이터를 NULL 로 변경함을 나타낸다.
다만 주의해야 할 점으로, 테이블 생성 시 NOT NULL 을 통해 NULL 값을 허용하지 않고 다음과 같은 제약 조건을 사용할 경우 에러가 발생할 수 있으니 코드 작성 전에 확인이 필요하다.
이는 간단한 상황이라 따로 예시를 언급하지 않는다.
FOREIGN KEY (userId) REFERENCES Users(userId)
ON DELETE SET NULL
ON UPDATE SET NULL;
4. SET DEFAULT
참조 데이터가 변경/삭제될 경우 해당 데이터를 '기본 값' 으로 변경함을 말한다.
테이블의 컬럼 속성을 정의할 때 @default('기본 값') 을 통해 데이터가 별도로 입력되지 않을 경우, 어떤 값으로 할당할 것인지 정하는 기본 값을 정의할 수 있는데, 이 값을 이용하겠다는 것이다.
만약 기본 값을 따로 설정하지 않았다면 자동적으로 NULL 이 할당된다.
FOREIGN KEY (userId) REFERENCES Users(userId)
ON DELETE SET DEFAULT
ON UPDATE SET DEFAULT;
그렇다면 이렇게 연관 관계를 갖는 테이블을 한번에 조회할 때는 어떤 방법을 사용해야 할까?
단순하게 생각해도 두 테이블을 따로따로 조회해서 일일이 비교하는 것은 너무 비효율적이다.
SELECT JOIN 연산자
SELECT 연산자의 활용법으로, 외래 키로 설정된 컬럼들을 연결 조회하는 방법이다.
JOIN 연산자는 두 테이블 사이의 공통된 데이터를 기준으로 하나의 테이블처럼 조회할 수 있게 해주는데 이를 통해 두 테이블의 연결된 컬럼, 외래 키를 기준으로 하나의 테이블처럼 조회하는 것이다.

다음과 같은 사진으로 예시를 들 수 있는데, userId 가 외래 키가 된다.
둘은 1 : N 관계로 JOIN 연산자는 userId 를 기준으로 탐색을 진행할 것이다.
이를 SQL 로 테이블을 만들어서 나타내면
CREATE TABLE Users
(
userId int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
email varchar(255) NOT NULL,
password varchar(255) NOT NULL
);
CREATE TABLE Posts
(
postId int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
userId int(11) NOT NULL,
title varchar(255) NOT NULL,
content varchar(255) NOT NULL,
FOREIGN KEY (userId) REFERENCES Users (userId)
);다음과 같이 테이블 작성 후에
INSERT INTO Users (userId, email, password)
VALUES (1, 'AAAA', '1234'),
(2, 'BBBB', '1234');
INSERT INTO Posts (userId, title, content)
VALUES (1, 'AAAA Title1', 'content'),
(1, 'AAAA Title2', 'content'),
(2, 'BBBB Title1', 'content'),
(2, 'BBBB Title2', 'content');이처럼 데이터를 추가해보자.
테이블 간의 관계로는 Post 테이블의 userId 가 Users 테이블의 userId 를 참조하고 있는 형식이다.
두 테이블을 한번에 조회하려면
SELECT p.postId, p.title, p.content, u.email
FROM Posts as p
JOIN Users as u
ON p.userId = u.userId;다음과 같이 작성할 수 있다.
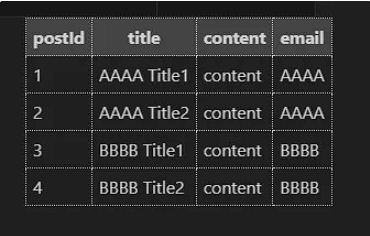
해서 Posts 테이블을 기준으로 Users 테이블의 email 까지 한번에 조회하는 모습을 볼 수 있다.
코드를 간단히 파악해보자.
JOIN 키워드를 통해 Posts 테이블과 Users 테이블을 동시에 조회하고 있다.
ON 키워드를 통해서는 어떤 컬림이 관계를 맺고 있는지 확인하고, 위 코드에서는 Posts 테이블의 userId, Users 테이블의 userId 임을 나타낸다.
as 키워드는 별칭을 말하는데, 이 코드 문법에 대해서는 지난 번에 작성한 내용이 있어 같이 첨부한다.
2024.10.08 - [내일배움캠프 학습/SQL] - #1. SQL 의 기초부터
#1. SQL 의 기초부터
1. 개념1. 데이터 베이스 : 여러 테이블을 포함하는 큰 틀2. 테이블 : 데이터가 행/열로 구성된 구조 - 행 : 데이터 레코드 - 열 : 데이터 속성customers 라는 테이블.그 안에 'customer_id', 'name', 'email', 'g
puudding.tistory.com
'내일배움캠프 학습 > Node.Js' 카테고리의 다른 글
| #6. ORM - Prisma (0) | 2024.12.17 |
|---|---|
| #5. Raw Query (1) | 2024.12.13 |
| #3. SQL 기초 (3) | 2024.12.11 |
| #2. 관계형 데이터베이스 RDB, AWS RDS 사용 (6) | 2024.12.04 |
| #1. 웹 브라우저, HTTP, 웹 서버/어플리케이션 (2) | 2024.11.20 |




