고정 헤더 영역
상세 컨텐츠
본문
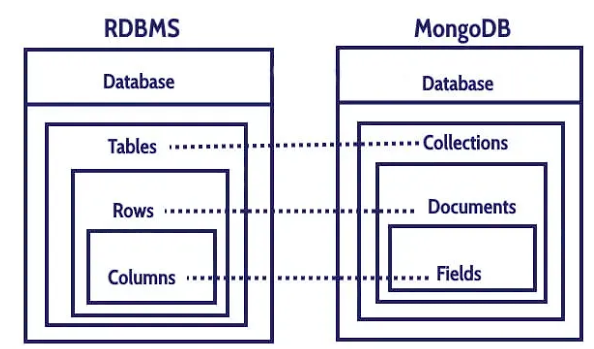
Prisma 란?
ORM(Object Realtional Mapping)의 일종으로 JS객체와 DB의 관계를 연결해주는 도구이다.
간단히 말해서 SQL 쿼리문 없이 JS만으로 DB의 관리를 가능하게 해주는 것이다. 여러 관계형 데이터베이스 RDB를 사용할 수 있는 이점 또한 챙길 수 있다.
이 ORM 의 종류에 여러개가 있는데, 그 중에서 Prisma 가 가장 학습하기 쉬워 이를 통해 진행한다.
Prisma vs Mongoose
지난 번에 활용했던 Mongoose 는 ODM의 일종으로 JS 객체를 Document 와 연결하는 방식이다. 이는 직접 데이터를 다루기 간편하고 관리가 간단하다는 등의 이점이 있지만 Prisma 는 ORM의 일종으로 JS 객체를 DB와 연결한다는 점에서 더 다양한 활용과 데이터 테이블의 형태를 Model 로 관리해 속성을 직접 결정할 수 있다는 등의 이점이 있다.
이 ORM을 사용하는 이유로는 크게 두가지가 있는데
1. 프로덕션에서 사용하는 DB가 언제 바뀔지 모르기에 재연결이 용이하다는 점
2. DB에서 사용하는 table 등의 속성이 변경되었을 때 빠른 수정이 가능하다는 점
이 있다.
이 내용만 보면 한없이 좋은 관리 기술같지만 단점 또한 존재한다.
1. JOIN 과 UNION 의 연산자를 동시 사용하는 등의 복잡한 쿼리 작성 시 이를 ORM 으로 구현하기 위해 SQL 보다 ORM 을 더 깊이 이해해야 하는 상황
2. 서브 쿼리를 포함하는 복잡한 쿼리 작성이 필요한 경우
3. ORM의 SQL로 변환해주는 시간조차 아까운 극한의 최적화 성능을 요구하는 경우
등이 있다.
특히 1번과 같은 경우는 ORM 의 사용 목적이 뒤집히는 경우라고 볼 수 있어 특히 그렇다.
이제부터 Prisma 의 활용 실습을 통해 어떤 방식으로 작동하는지를 알아보고자 한다.
Prisma 시작하기
# yarn 프로젝트를 초기화합니다.
yarn init -y
# express, prisma, @prisma/client 라이브러리를 설치합니다.
yarn add express prisma @prisma/client
# nodemon 라이브러리를 DevDependency로 설치합니다.
yarn add -D nodemon
# 설치한 prisma를 초기화 하여, prisma를 사용할 수 있는 구조를 생성합니다.
npx prisma init매번 그렇듯 프로젝트 초기화부터 시작하고 진행한다.
여기에 prisma 라이브러리 또한 함께 설치한다.
초기화 진행 후에 프로젝트를 보면 여러개의 파일이 생성될 텐데, 하나씩 보자면
1. schema.prisma
이 파일은 prisma 가 사용할 DB를 설정하기 위해 사용하는 파일로 절대 지우면 안된다.
2. root/.env
외부에 공유되어선 안되는, 보안이 필요한 정보들이 저장되어 있는 파일이다.
3. root/.gitignore
git에 업로드할 경우 push에 포함되지 않도록 하는 파일을 저장하는 것으로, prisma의 경우 파일의 경로를 같이 저장하곤 한다.
schema.prisma
위에서 언급했듯 prisma 가 사용할 DB의 설정 정보를 정의하기 위해 사용하는 파일이다.
라이브러리를 설치하고 나면

다음과 같은 파일이 하나 생성될 텐데 이 안에는
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}이와 같은 두개의 구문이 기본 작성되어 있다. 하나씩 알아보자.
1. generator
prisma 클라이언트를 생성하는 방식을 설정하는 구문이다. 이 항목은 간단하게만 알아두고, 이번 실습에서는 수정하지 않는다.
2. datasource
DB에 대한 정의를 하기 위해 사용한다.
prisma 가 어떤 DB엔진을 사용할 것인지, DB의 위치(URL)은 어디인지 등을 설정한다.
우리는 이번 실습에서 mysql을 사용할 것이기 때문에 provider의 "postgresql" 을 "mysql" 로 바꿔주어야 한다.
url = env(" ~ ") 는 .env 파일로 연결된다
.env

여기서 DATABASE_URL 을 RDS에서 대여했던 DB 인스턴스의 주소를 가져와 바꿔준다.
데이터베이스 URL
prisma가 어떤 DB와 연결될 것인지 알려주는 주요한 정보이며, DB엔진의 유형, 사용자 아이디, 패스워드 등의 정보가 같이 포함되어 있다.
이는 4가지 유형으로 나눌 수 있는데
1. Protocol
prisma 가 사용할 DB 엔진을 말한다. mysql, sqlite가 이해 해당한다.
2. Base URL
DB의 엔드 포인트, ID/PW, 포트 번호를 나타낸다.
<Id>:<Password>@<RDS Endpoint>:<Port>의 형태로 구성되어 있다.
3. Path
MySQL에서 사용할 DB이름을 설정하는 요소이다.
4. Arguments
Prisma에서 DB 연결에 필요한 추가 옵션을 표시한다. 최대 커넥션 갯수, 타임아웃 등이 이에 포함된다.
이러한 정보를 통해 우리가 사용할 DB의 URL을 구성해보면
mysql://root:abcd1234@express-database.c9ig8g20a5my.ap-northeast-2.
rds.amazonaws.com:3306/prisma_CURD다음과 같이 작성할 수 있다.
mysql 을 사용하며 DB의 URL 주소를 나타내었고, 3306포트를 사용하기로 하였다는 정보를 포함하고 있다.
Prisma Model
특정 테이블과 컬럼의 속성값을 입력해 DB와 Express 프로젝트를 매핑하는 과정이 이루어지는 곳이다.
model 구문은 prisma를 사용할 때 특히 많이 작성하게 될 구문이며, prisma 가 사용할 DB의 테이블 구조를 정의하기 위해 사용한다.
이는 schema.prisma 파일에서 작성하는데 이렇게 작성한 정보를 바탕으로 Prisma Client 를 통해 JS에서 MySQL의 테이블을 조작할 수 있도록 도와준다.
예시로 Products 테이블을 하나 만들어보자.
// schema.prisma
model Products {
productId Int @id @default(autoincrement()) @map("productId")
productName String @unique @map("productName")
price Int @default(1000) @map("price")
info String? @map("info") @db.Text
createdAt DateTime @default(now()) @map("createdAt")
updatedAt DateTime @updatedAt @map("updatedAt")
@@map("Products")
}다음과 같이 작성할 경우 4개의 컬럼을 가진 테이블이 만들어진다.
코드를 살펴보면
productId Int @id @default(autoincrement()) @map("productId")@id, @autoincrement() 속성을 통해 고유 id를 나타내기 위한 컬럼이다.
테이블에서는 productId 라는 컬럼명으로 표기되며 @map("productId") 를 통해 Node에서도 같은 변수명으로 사용할 수 있도록 해주었다.
produectId 의 경우 데이터 타입을 Int 로 정의해주었고, 다른 컬럼들에는 String 이 정의된 경우가 있는데 한가지 눈에 띄는 것은 String? 으로 물음표가 같이 붙은 경우가 있다.
이 데이터 타입 뒤에 ? 물음표가 붙는 경우는 NULL 값을 허용하는 컬럼이라는 것을 나타내며, 물음표가 붙지 않은 컬럼은 모두 NOT NULL 의 속성을 갖게 된다.
또한 테이블 정의에 가장 마지막에 @@map("Products") 를 통해 해당 테이블의 이름을 Node에서 어떻게 사용할 것인지 정의해주었다. 다른 컬럼의 경우 @ 로 문자를 하나만 붙여 주었는데, 이를 두개 붙여주느 이유는 대문자와 소문자를 구분하기 위함으로 이렇게 작성하지 않을 경우 대문자가 전부 소문자로 치환된다. 이를 방지하기 위해 @@로 사용해주었다.
이 테이블의 요구사항을 표로 나타내보면
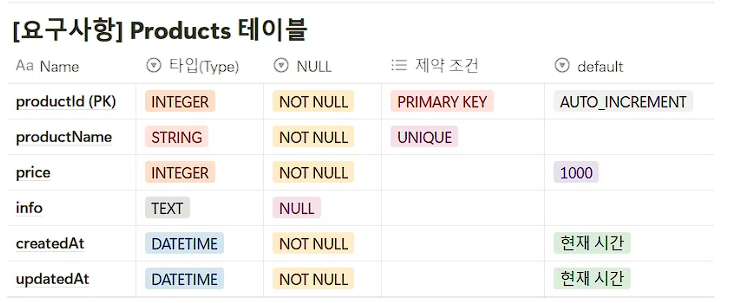
다음과 같이 나타낼 수 있을 것이다.
'아이템 시뮬레이터' 프로젝트를 진행하면서 느낀 바로는, 개발 초기에 API 명세서를 비롯해 이런 요구사항들의 속성을 정확히 하고 개발에 들어가는 것이 좋다는 것이었다.
명확하게 구현 요구사항이 정해진 개발은 가이드라인이 주어진 셈으로 기준이 있어 팀원 간에도 의사소통의 문제가 생길 여지가 적지만, 고정되지 않고 계속 변동될 수 있는 요구사항은 개발 중에 혼선을 야기할 수 있어 큰 문제를 갖게 된다.
따라서 요구사항을 먼저 명확히 하고, 그 다음에 테이블의 구조를 작성하는 것이 순서상 옳다는 것이다.
이를 실습을 통해 진행해보자.
실습 : Post 테이블 생성

직접 학습을 하며 느낀 결론은, 여러 개의 컬럼 중에서도 특히 주의해야 할 사항들이 있다는 것이다.
Primary Key 를 통해 id 값을 부여할 컬럼은 어떤 것인지, NULL 을 허용하는 컬럼이 있는지, 있다면 어떤 컬럼인지 등 말이다.
또한 이 Posts 테이블에는 적용되지 않았지만 추후 다른 테이블과 관계를 맺을 Foreign Key는 어떤 컬럼이고 어떠한 관계를 맺는지 등에 대해 먼저 파악하는 것이 중요하다.
이 Posts 테이블을 schema 로 작성하면 다음과 같이 나타낼 수 있다.
// schema.prisma
model Posts {
postId Int @id @default(autoincrement()) @map("postId")
title String @map("title")
content String @map("content") @db.Text
password String @map("password")
createdAt DateTime @default(now()) @map("createdAt")
updatedAt DateTime @updatedAt @map("updatedAt")
@@map("Posts")
}
이후 터미널에 다음과 같은 명령어를 입력해 테이블을 생성할 수 있다.
# schema.prisma 파일에 설정된 모델을 바탕으로 MySQL에 정보를 업로드합니다.
npx prisma db push

Posts 테이블 안에 제시한 컬럼들이 모두 정의되었고, postId 의 경우 Primary Key를 적용해 고유 id 값을 나타내는 열쇠 모양의 아이콘으로 생성된 것을 확인할 수 있다.
'내일배움캠프 학습 > Node.Js' 카테고리의 다른 글
| #8. JWT(Json Web Token) (2) | 2024.12.19 |
|---|---|
| #7. Prisma Method, 게시글 API 실습 (1) | 2024.12.18 |
| #5. Raw Query (1) | 2024.12.13 |
| #4. SQL 제약 조건 (1) | 2024.12.12 |
| #3. SQL 기초 (3) | 2024.12.11 |




