고정 헤더 영역
상세 컨텐츠
본문
문자 데이터를 바꾸고, Group by 절까지 같이 사용하는 실습을 진행한다.
1. 서울 지역 음식 타입 별 평균 음식 주문 금액 구하기
출력 : '서울', '타입', '평균 금액'
키워드는
1. 서울 지역
2. 음식 타입
3. 평균 주문 금액 (Avg)
로 볼 수 있다.
SELECT SUBSTR(addr, 1, 2) '지역',
cuisine_type,
AVG(price) '평균 금액'
FROM food_orders fo
WHERE addr like '%서울%'
GROUP by 1,2 //GROUP by SUBSTR(addr, 1, 2), cuisine_type 와 같은 의미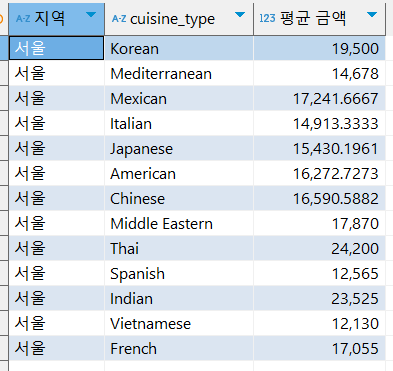
2. 이메일 도메인 별 고객 수와 평균 연령 구하기
키워드는
1. 이메일 도메인
2. 고객 수 (Count)
3. 평균 연령 (Avg)
로 볼 수 있다.
더보기
실습 중 이 데이터 테이블을 보면 이메일이 @의 앞 글자수가 모두 8로 통일된 것을 볼 수 있다.
편의상 그렇게 작성된 것이며, 따라서 도메인은 10번째부터 탐색한다.
: substr(email, 10)
SELECT SUBSTR(email, 10) '도메인',
count(1) '고객 수',
AVG(age) '평균 연령'
FROM customers c
group by substr(email, 10)
여기서의 substr 은 시작 위치만 정하고 글자 수 끝까지 조회하도록 하기 위해 조회 글자 수 를 입력하지 않았다.
3. ' [지역(시도)] 음식점 이름(음식종류)' 컬럼 만들고, 총 주문건수 구하기
'컬럼을 만든다' 라는 제시에서 concat 함수를 사용해야 한다는 것을 알 수 있다.
SELECT CONCAT('[', SUBSTR(addr, 1, 2) ,']',
restaurant_name, ' (', cuisine_type, ')') '음식점',
count(1) '주문 건수'
FROM food_orders fo
group by 1
concat 함수를 통해 특수문자, 컬럼 명 등을 포함시켰고
그 안에 정해진 글자 수만 출력하도록 하는 substr 함수 또한 포함되어 있다.
주문 건수는 그룹 별로 전체를 조회하기 위해 1 을 인자로 넣어주었다.
사실 컬럼을 만드는 과정이 생소할 뿐, 데이터 조회 자체는 어렵지 않은 문제였다.
'내일배움캠프 학습 > SQL' 카테고리의 다른 글
| #8. IF/CASE 실습 (1) | 2024.10.23 |
|---|---|
| #7. IF/CASE 문법 (5) | 2024.10.23 |
| #5. 문자 데이터 가공 - 형태 변화 (2) | 2024.10.18 |
| #4. 문제 풀이 - 주문 금액 조회 (0) | 2024.10.18 |
| #3. 그룹 연산, 정렬, 구조 정리 (0) | 2024.10.11 |




